Figure 1: Processing flow of the Image Collector II.
We describe a system gathering over one thousand images from the World-Wide Web for one keyword. It is called the Image Collector II. The system has the following properties: (1) integrating a sophisticated keyword-based search method and an image-feature-based search method in a non-interactive manner, (2) on-demand image gathering using commercial text search engines, and (3) second image gathering for gathering over one thousand images by extracting words with high frequency from all HTML files with embedded output images in an initial image gathering. This three properties enable us to gather a large number of images related to one keyword easily.
Web image gathering, image search engine, image database
Due to the recent explosive growth of the World-Wide Web, we can easily access a large number of images from the Web. Therefore, we can consider the Web as a huge image database. However, most of those images on the Web are not categorized in terms of their contents and are not labeled with related keywords. We can use commercial image search engines such as Google Image Search and Ditto to search the Web for image files by giving them keywords. However, most of image search engines search for images based only on keywords in HTML documents that include images, and they do so without analyzing the content of the images.
To achieve an image search for the Web based on not only keywords but also the content of the images, we proposed an automatic image-gathering system from the Web that is constructed by integrating a keyword-based search method and an image-feature-based search method, which is called the Image Collector [5]. In the system, a user first gives query keywords to the system, and then obtains images associated with the keywords. First, using the existing commercial Web search engines for HTML documents, the system gathers images embedded in HTML documents related to the query keywords. Next, the system selects output images from collected images based on extracted image features. However, the system gather only several hundreds images by such one-time processing.
Our initial objective for this system was to gather a large number of images for web image mining research, but the number of gathered images turned out to be insufficient [6].
Thus, in this paper we propose a new method to gather more and more images from the Web. First, we extract words with high frequency from all HTML files with embedded output images in the first image-gathering processing, and using them as keywords we gather images from the Web again. Finally, we can obtain more than one thousand images for one keyword. In addition, in this paper we also propose word-feature-based image selection for improving accuracy of final output images.
Some Web image search systems such as WebSeer [1], WebSEEk [4] and Image Rover [3] have been reported so far, which can be regarded as an integration of a keyword-based search and an image-based-feature-based search. However, these systems carry out two kinds of searches one after the other in an interactive manner, and require gathering images over the Web in advance and making big indices of images on the Web. In contrast to those systems, our system only needs one-time input of query keywords and does not require making a large index in advance due to exploiting existing Web text search engines. Then, we call our system not a ``search'' system but a ``gathering'' system.
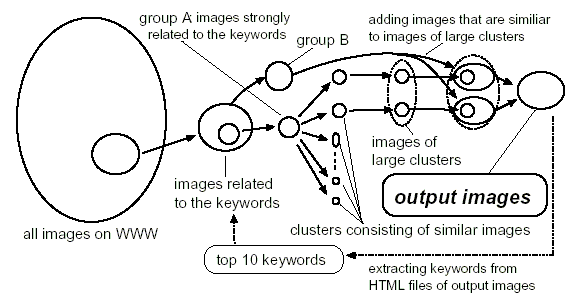
The processing of the Image Collector II consists of collection and selection stages. In addition, it extracts additional keywords and repeats two kinds of stages during a second image gathering. Figure 1 shows the processing flow.
In the selection stage, the system selects more appropriate images for the query keywords out of ones gathered in the collection stage. The selection is based on the image features described below.
After this image-feature-based selection, our system carries out the second selection for group B images by using word vectors extracted from the HTML documents with embedded images. Introducing the word vectors enables it to eliminate images embedded in the HTML documents whose topics are irrelevant and to ignore them.
In our image-gathering method, the more URLs of HTML documents we obtained, the more images we could gather. However, for one set of query keywords, the number of URLs obtained from Web search engines was limited because commercial search engines restrict the maximum number of URLs returned for one query. Thus, we propose a method to generate automatically new sets of query keywords for search engines.
The system extracts the top ten words (only nouns, adjectives, and verbs) with high frequency except for initial query keywords from all HTML files with embedded output images of the initial image gathering, and regards them as subsidiary query keywords. It generates ten sets of query keywords by adding each of ten subsidiary words to a main keyword, and then obtains a large number of URLs for the ten sets of query keywords. Then, for the second image gathering, using obtained URLs, the system goes through the collection and selection stages again.
Table 1 shows experimental results of the initial and second image gathering for eight keywords. It describes the number of URLs of HTML documents obtained from search engines, the number of images collected from the Web, and the number of selected images by three methods, image-feature-based, combination of image-feature-based and word-feature-based, and combination of image-feature-based and LSI-compressed-word-feature-based. It also describes the precision rate of the collected and selected images in parentheses. The precision represents the ratio of relevant images and was computed by the subjective evaluation.

Thanks to introducing the second image gathering, the number of URLs obtained from the Web search engine and the number of selected images are 5.1 times and 2.2 times as many as ones in case of the initial image gathering on average. For ``lion'', we extracted ten words as new subsidiary keywords. They were ``safari'', ``zoo'', ``park'', ``elephant'', ``tiger'', ``Africa'', ``group'', ``giraffe'', ``mane'', and ``head''. Finally, we obtained 1171 images with a 64.4% precision on average for the LSI-based selection.
In this paper, we described a method, an implementation, and the experiments of an automatic image-gathering system for the web. We gathered more than one thousand images for one keyword and achieved the high precision of about 70% without any knowledge about target images by using word vectors and the LSI method.
In the present implementation, we use simple image features for the image selection. In future work, we plan to exploit more sophisticated image features to improve the precision rate. Moreover, we will apply gathered images for our web image mining project.