平成29年度 卒業研究論文
モバイルGPU活用のための深層学習
モデルコンバータの実現
電気通信大学 情報理工学部
総合情報学科 メディア情報学コース
1410009 泉 裕貴
Date:
平成30年2月6日
Abstract:
iPhoneを始めとするモバイル端末の性能は年々向上し高い演算能力を持つようになったため、学習済みモデルから深層学習の推論をモバイル端末上で行うことが可能となってきた。しかし、最新のネットワークは枝分かれのあるものやネットワークが深くパラメータ数が非常に多いものとなっており、今後更に複雑なネットワークが出現することが予想される。このようなネットワークをモバイル端末上で実装するためには長文且つ難解なコードを書く必要があるために人手で書くことは困難である。そこで本研究では、計算機上で既存の深層学習フレームワークChainerを用いて学習した際に生成されるモデルファイルから、深層学習の推論を行うSwift言語のコードを自動生成することができるコンバータChainer2Sを作成した。また、実験によって深層学習アプリケーションの実装へのGPU利用の必要性を示し、深層学習の演算処理にGPUに用いる実装方法についても比較を行い、最適な実装方法を明らかにした。
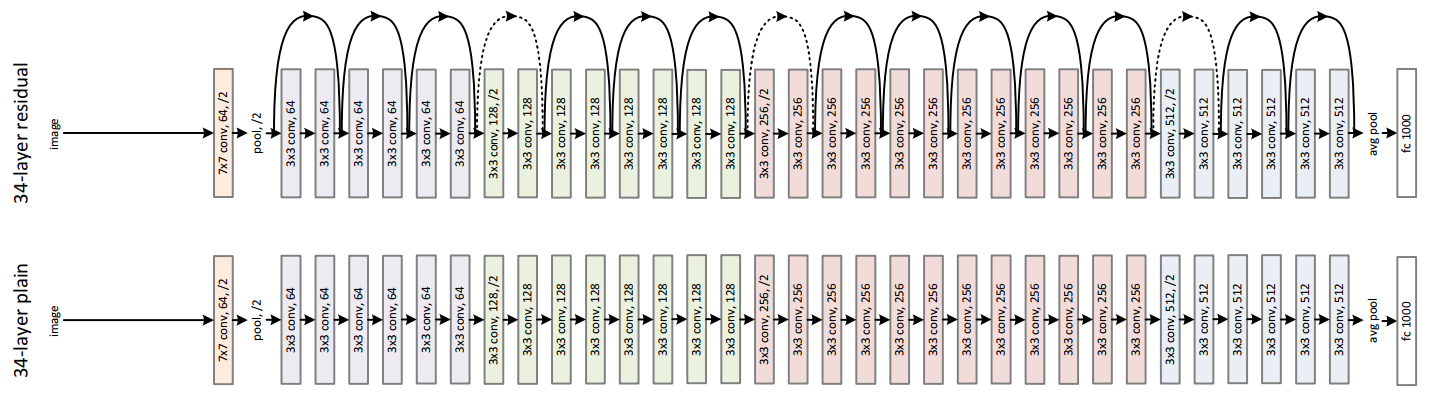
ImageNet Large Scale Visual Recognition Challenge 2012(ILSVRC2012)[#!imagenet!#]においてAlexNet[#!alexnet!#]が発表され、深層学習が他手法よりも高い性能を示して以降、画像認識や自然言語処理など様々な分野において深層学習が注目され、研究が盛んに行われるようになった。深いネットワーク構造がより豊かな特徴を表現され高い精度を得ることができるため、GoogLeNet[#!googlenet!#]やResidualNet[#!resnet!#]のような深く複雑なネットワークが出てくるようになった。それぞれのネットワーク図を図![[*]](/usr/share/latex2html/icons/crossref.png) 、図に示す。
、図に示す。
また、それと同時にモバイル端末やロボット、自動運転車などの計算リソースの限られた端末に深層学習を適用するための研究も数多くされている。
モバイル端末等ではリアルタイム処理が重要であり、深層学習の大量の演算を高速に処理する必要性がある。しかし、深層学習はGraphics Processing Unit(GPU)を複数用いた高い演算処理能力を前提にしたものであるため、計算リソースの限られた端末での実装は困難である。この問題を解決するためにパラメータ数、演算量を削減するためのネットワーク構造や計算方法などが数多く開発されている。
一方で、iPhoneを始めとするモバイル端末はCentral Processing Unit(CPU)、GPUの性能が年々向上し、高い演算能力を持つようになったため、学習済みモデルから深層学習の推論を行うことはモバイル端末上でも利用可能となってきた。CPUのみで演算の処理を行う実装は数多く存在し、GPUを利用した実装も現れてきている。深くパラメータ数が非常に多いネットワークをモバイル端末で実装するためには、演算処理のより優れたGPUの利用が求められる。また、最高性能を示している複雑なネットワークや、高速化を図ったネットワークを実装しようとした場合にコードが長文化、難解化してしまい人手で書くのは困難である。
Figure:
GoogLeNetのネットワーク図([#!googlenet!#]より引用)
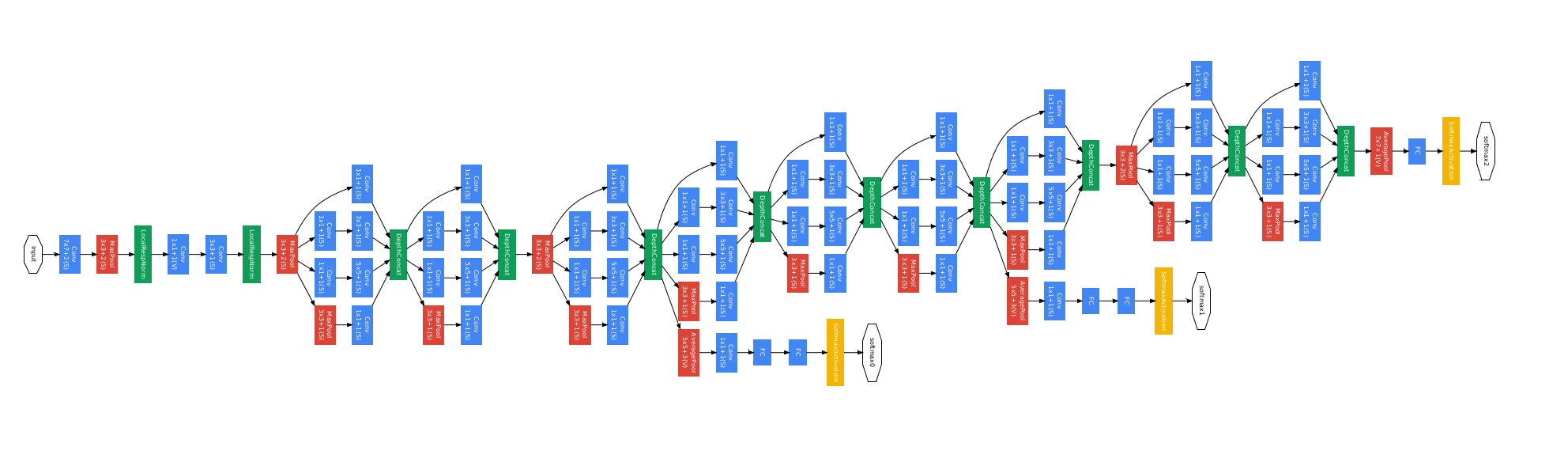 |
Figure:
ResidualNetのネットワーク図([#!resnet!#]より引用)
 |
本研究では、計算機上で既存の深層学習フレームワークChainerを用いて学習した際に生成されるモデルファイルから、深層学習の推論を行うSwift言語のコードとパラメータファイルを自動生成することができるコンバータChainer2Sを作成し、iOS端末上で簡単且つ高速に深層学習の推論を可能にすることを目指す。この時、CPUよりも演算処理能力の優れているGPUを利用する。
本論文の構成は以下のようになっている。
1章 はじめに
この研究の背景、目的を記載する。
2章 関連研究
関連研究を紹介する。
3章 深層学習アプリケーションの作成手順
本研究のコンバータChainer2Sを用いた深層学習アプリケーションの作成手順について説明する。
4章 手法
本研究の手法について述べる。
5章 実験
実験内容とその結果について述べる。
6章 考察
実験の結果に対する考察を述べる。
7章 まとめと今後の課題
全体のまとめと今後の課題について述べる。
付録
利用可能なノード一覧と実験で得られたデータを記載する。
モバイル端末では、計算機に比べて計算リソースやメモリ容量に大きな制限がかかる。そのため、モバイル端末に深層学習を実装しようとした場合に演算量の多さが問題となる。特に、ネットワークの各層の中で畳み込み層の演算が全体の演算時間の大部分を占めるため、畳み込み層の演算を高速化することが、深層学習をモバイル端末に実装する上で重要であり、以下のようなCNNの高速化に関する研究が行われている。
また、モバイル端末上で深層学習を実装するために、既存の深層学習フレームワーク上に設計し、モバイル端末へ適用したものや、新しくモバイル端末用のフレームワークを開発するなど数多くの実装方法が存在し、以下のようなものがある。
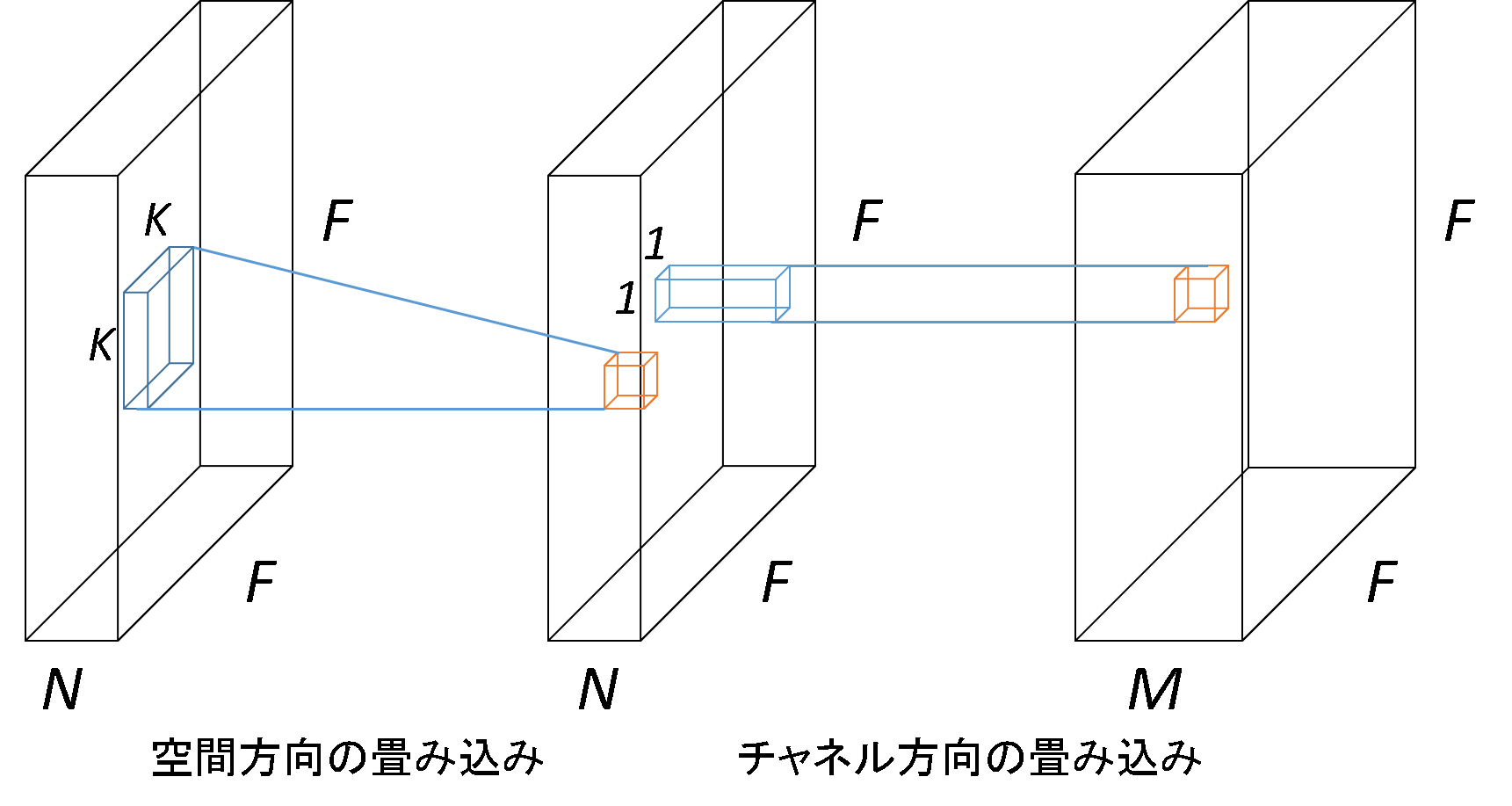
Howardらは、畳み込み層をdepthwise separable convolution[#!dsconvolution!#]に置き換え、width multiplier、resolution multiplierの2つのハイパーパラメータを導入することにより、非常に小さな精度低下の代わりにネットワークの演算量とパラメータ数を大幅に削減した[#!mobilenet!#]。depthwise separable convolutionは、通常の畳み込み層を空間方向の畳み込み演算とチャネル方向の畳み込み演算の2つの畳み込み演算に分離することで、演算量を8分の1程度に減らすことができる。以下の図に概略図を示す。width multiplierは、ネットワークを全体的にチャネル方向に関して縮小するものであり、resolution multiplierは、入力画像のサイズを縮小するものである。これらのハイパーパラメータを導入することで、容易にネットワークを軽量化、高速化できるようにした。
Figure:
Depthwise Separable Convolutionの概略図
 |
Ghoshは、depthwise separable convolution[#!dsconvolution!#]に加え、パラメータの重みが十分に小さいときに刈り取るPruningやパラメータのハフマン符号化、Parametric Rectified Linear Units(PReLU)の利用、全結合層の代わりにglobal average poolingを用いるなどの工夫を行うことで、精度を落とすことなく演算量を削減したネットワークを開発した[#!quicknet!#]。
深層学習フレームワークで学習したモデルをiOSで使用するために、フレームワーク自体がiOS上で動作するように設計されたものとして、Caffe for iOS1、TensorFlow2、OpenCV3などがある。また、既存のフレームワーク上に設計され、モバイルへの適用が考慮されたものとしてCaffe24などがある。しかし、これらは全てCPUのみを利用した演算処理である。
CoreMLは、iOS11から新しく追加された機械学習API群である5。既存の深層学習フレームワークであるKerasやCaffeなどで作成した学習済みモデルを変換ツールを用いてmlmodelファイルを作り、アプリケーションの中で読み込むのみで、深層学習の推論を簡単に実装することが出来る。CoreMLは、モデルの演算をCPU、GPUのどちらで処理するかを自動的に判断し実行する。しかし、実装されているレイヤーの種類は限定されていて、対応されていない新規に開発されたレイヤーを使用したい場合に、低級言語であるMetal Shading Languageでレイヤーの処理を書く必要があるため、高度なスキルが要求される。
Tannoらは、学習済みモデルファイルをiOS上で動作可能にする深層学習モデルコンバータ、Caffe2C(Chainer2C)を開発した[#!caffe2c!#]。これは、Caffe(Chainer)で学習した後に生成されるパラメータファイルから、モバイル端末でも実行可能なC言語のコードを自動生成するものである。全ての学習パラメータが定数配列としてC言語コードに組み込まれ、学習済みモデルファイルを実行するために必要なファイルを全て含んだC言語コードを生成する。また、高速化の工夫としてim2col操作により畳み込み演算を行列積で計算できるようにし、高速行列演算ライブラリであるBLASを利用することでSIMD(NEON)命令、マルチスレッド処理を行っている。しかし、Caffe2C(Chainer2C)はiOSとAndroid両対応であるためGPUは使用していない。
そこで本研究では、高度なスキルを必要としないモバイル深層学習アプリケーションの作成を可能とするコンバータの作成を目指す。また、iOSに特化することによりCPUよりも演算処理能力の優れたGPUを利用し、iOS上での演算の高速化を図る。
本研究のコンバータを用いた深層学習モバイルアプリケーションの作成の手順について説明する。
- 学習用データセットの用意する。
- 深層学習フレームワークのChainerを用いてネットワークを学習し、モデルファイルを作成する。
- コンバータChainer2Sを用いて学習済みのモデルファイルからSwift言語のコードとパラメータファイルを生成する。
- iOS深層学習アプリケーションのGUI部分のコードを作成する。
- 生成したSwift言語のコード、パラメータファイル、GUIのコードからアプリケーションを作成する。
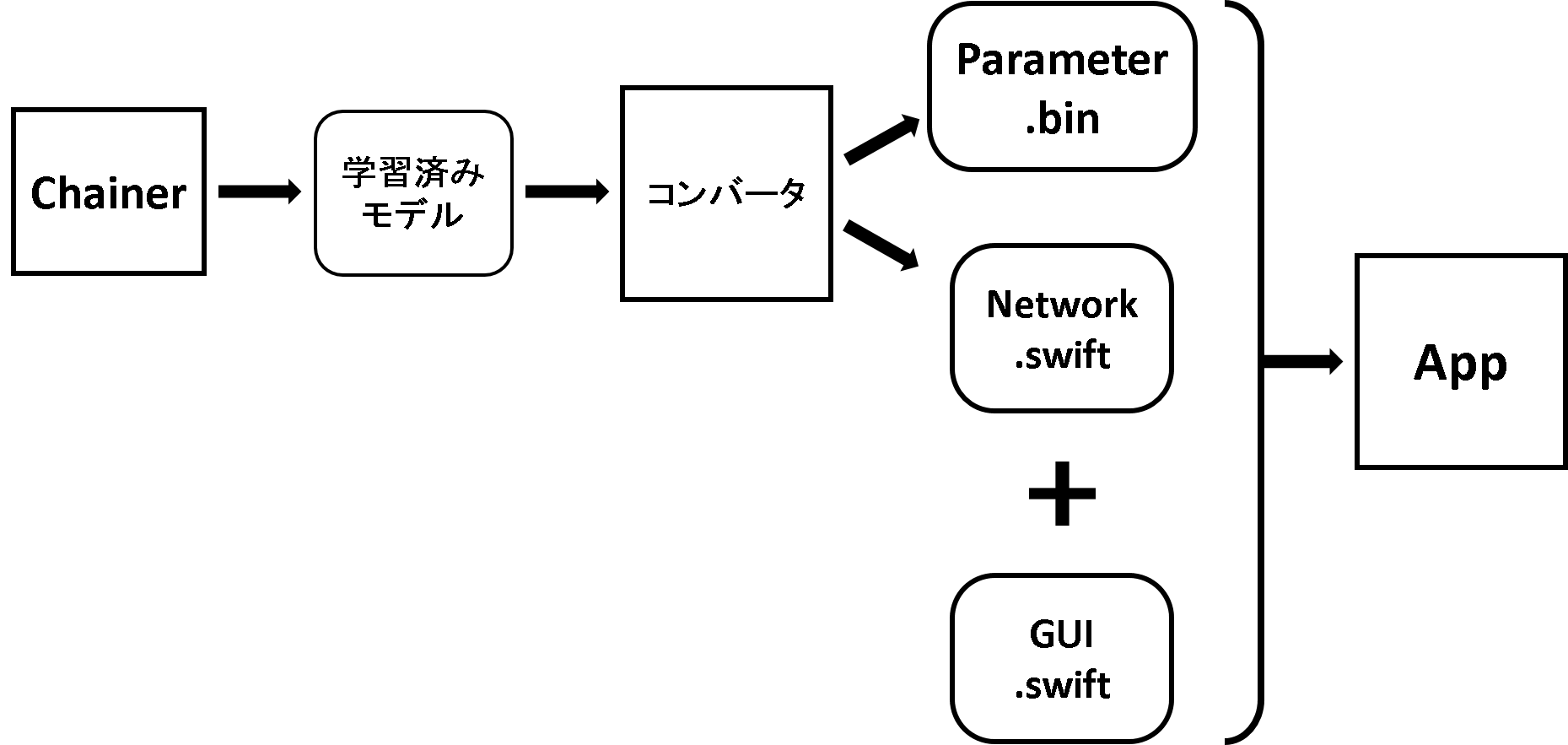
まず、計算機上で深層学習フレームワークであるChainerを用いてネットワークを学習し、学習済みモデルファイルを用意する。Chainerでは、ネットワークで一度順伝搬計算を行うと、ネットワークの各レイヤーはチェーンによって繋がる。これにより、出力からネットワークを遡ることが可能になり、各層の種類やパラメータ、フィルターサイズ等の情報を取得する。これらの情報から、Swift言語のコードとパラメータファイルを生成する。また、カメラから画像の取得やGUIのコーディングを行い、パラメータファイルなどと合わせることで深層学習アプリケーションを作成することができる。深層学習アプリケーションの作成の流れ図を以下の図に示す。
Figure:
深層学習アプリケーションの作成の流れ
 |
Chainerで使用する画像などの入力やネットワークの中間出力などのデータは、単なるベクトルではなく、計算グラフを保持するVariableで構成する必要がある。このVariableという構造体を使用することによってネットワークで順伝搬計算を一度行うことで、ネットワークの各ノードはチェーンで繋がり、逆伝搬計算をすることが可能になる。
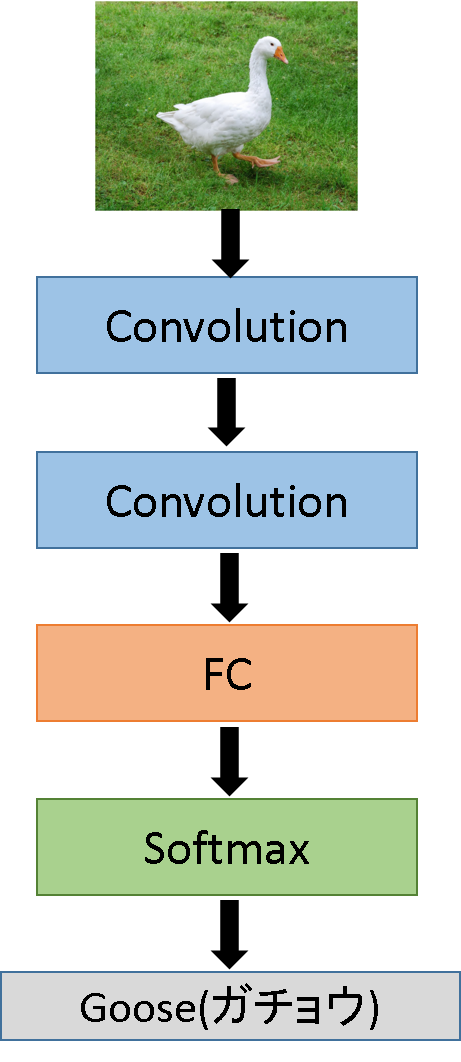
本研究では、この機能を利用して、一度順伝搬計算を行うことでネットワークの各ノードをチェーンで繋げる。これにより、ネットワークの出力から属性creatorを得ることでネットワーク最後のレイヤーがどのようなレイヤーであるかを知ることができる。そのレイヤーのinputs[0]を得ることでそのレイヤーへの入力(1つ前のレイヤーの出力)を得ることができる。同様にcreatorを調べてその入力を辿ることを繰り返すことでネットワーク全てを遡る。この時、レイヤーが畳み込み層や全結合層などの場合、inputsのリストに重みとバイアスのパラメータを抱えており、inputs[1]に重みのパラメータ、inputs[2]にバイアスのパラメータが格納してある。これを図解したものを図として以下に示す。また、簡単なCNNの例を図に示す。
このようにネットワークの出力からネットワークの最初のレイヤーまでを辿り、ネットワークの各レイヤーの種類やパラメータなどの情報をまとめて1つのリストとして作成する。そのリストを用いてSwift言語のネットワークのコードとパラメータのバイナリファイルを作成する。Swift言語のコードの作成については、4.2節で説明する。バイナリファイルは、各層の重みとバイアスをそれぞれ分けてファイル化する。この時、畳み込み層の重みパラメータのシェイプは[outputChannels][kernelHeight][kernelWidth][inputChannels]、全結合層の重みのシェイプは[outputChannels][inputChannels]である必要がある。注意点として、畳み込み層の直後の全結合層の重みパラメータのシェイプは畳み込み層と同様に、[outputChannels][kernelHeight][kernelWidth][inputChannels]としなければならない。
Figure:
Chainerにおけるネットワーク構造
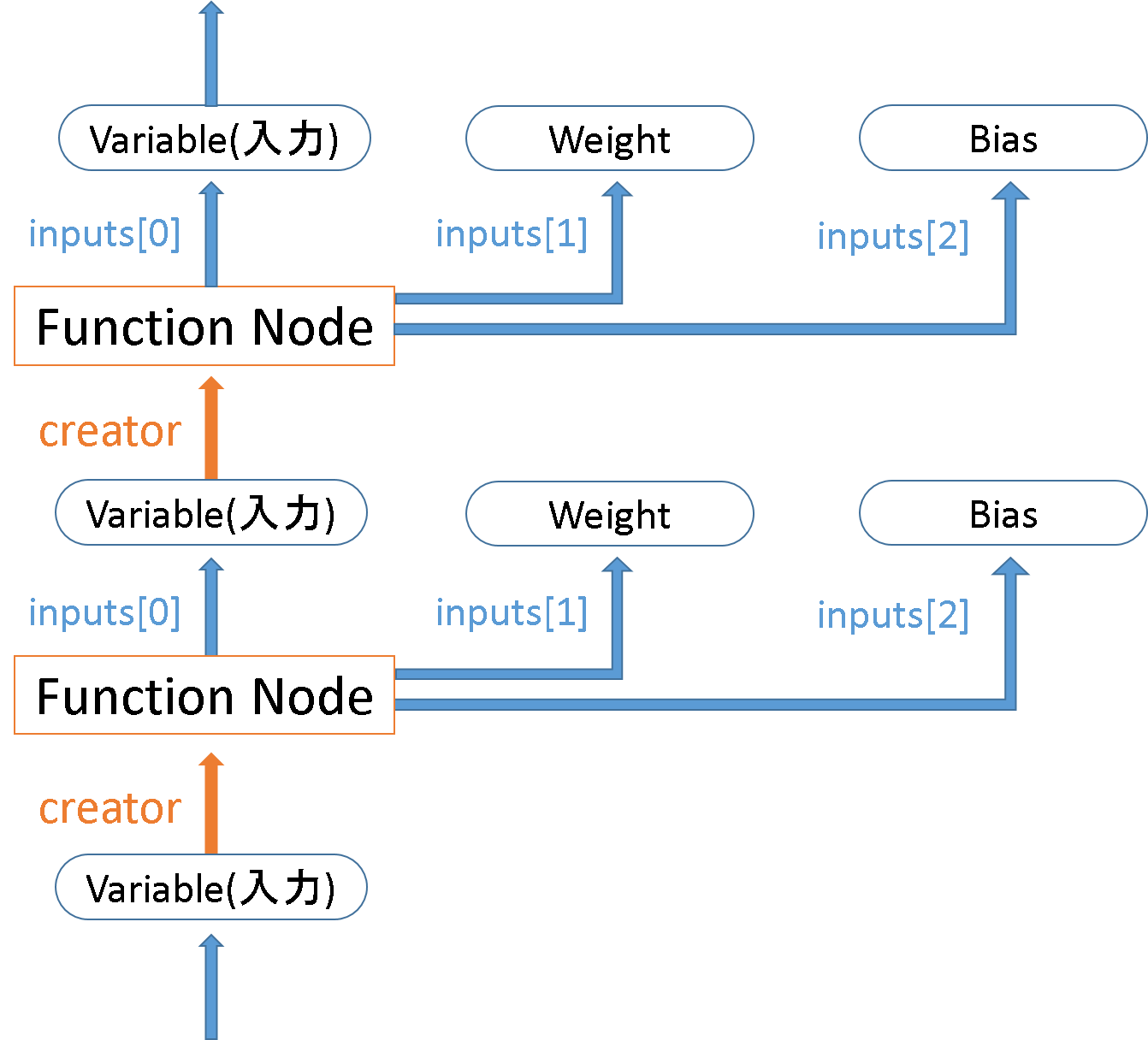 |
Figure:
CNNの例
 |
本研究で作成したコンバータChainer2Sが生成するネットワークのコードは、Metal Performance Shaders(MPS)フレームワークの一部であるMPSNNGraphクラスを利用している。MPSフレームワークは、GPU上で画像処理や行列演算などを実行させる計算カーネルのライブラリであり、MPSを使用することで深層学習のGPU実行を実現している。MPSNNGraphは、ニューラルネットワーク中の画像とフィルタノードが最適化されたグラフ表現である。グラフを構築した時に解析され、どのノードが入力に必要であり、どのノードが出力として生成されるかが決まる。これにより、出力として生成されるノードを計算するために必要でないノードは無視し、いくつかのノードはパフォーマンス向上のために他のノードと内部的に連結したグラフとなる。
MPSNNGraphの実装例としてVGG16[#!vgg16!#]の実装を図として以下に示す。MPSCNNConvolutionDataSource関数によって、バイナリファイルから重みやバイアスのパラメータのロードを行う。また、MPSCNNConvolutionDescriptor関数によって、入力チャネルや出力チャネル、フィルターサイズ、活性化関数などの設定を行う。これら2つの関数を呼び出すDataSource関数を作成することで畳み込み層や全結合層のノードを実現している。この時、全結合層のMPSCNNConvolutionDescriptorに入力するフィルターサイズは1 x 1とする。しかし、畳込み層の直後の全結合層では、MPSCNNConvolutionDescriptorに入力するフィルターサイズはkernelHeight x kernelWidthとし、inputChannelsは前の畳み込み層のoutputChannnelsとする必要がある。
実装時の問題点として以下のことが挙げられる。
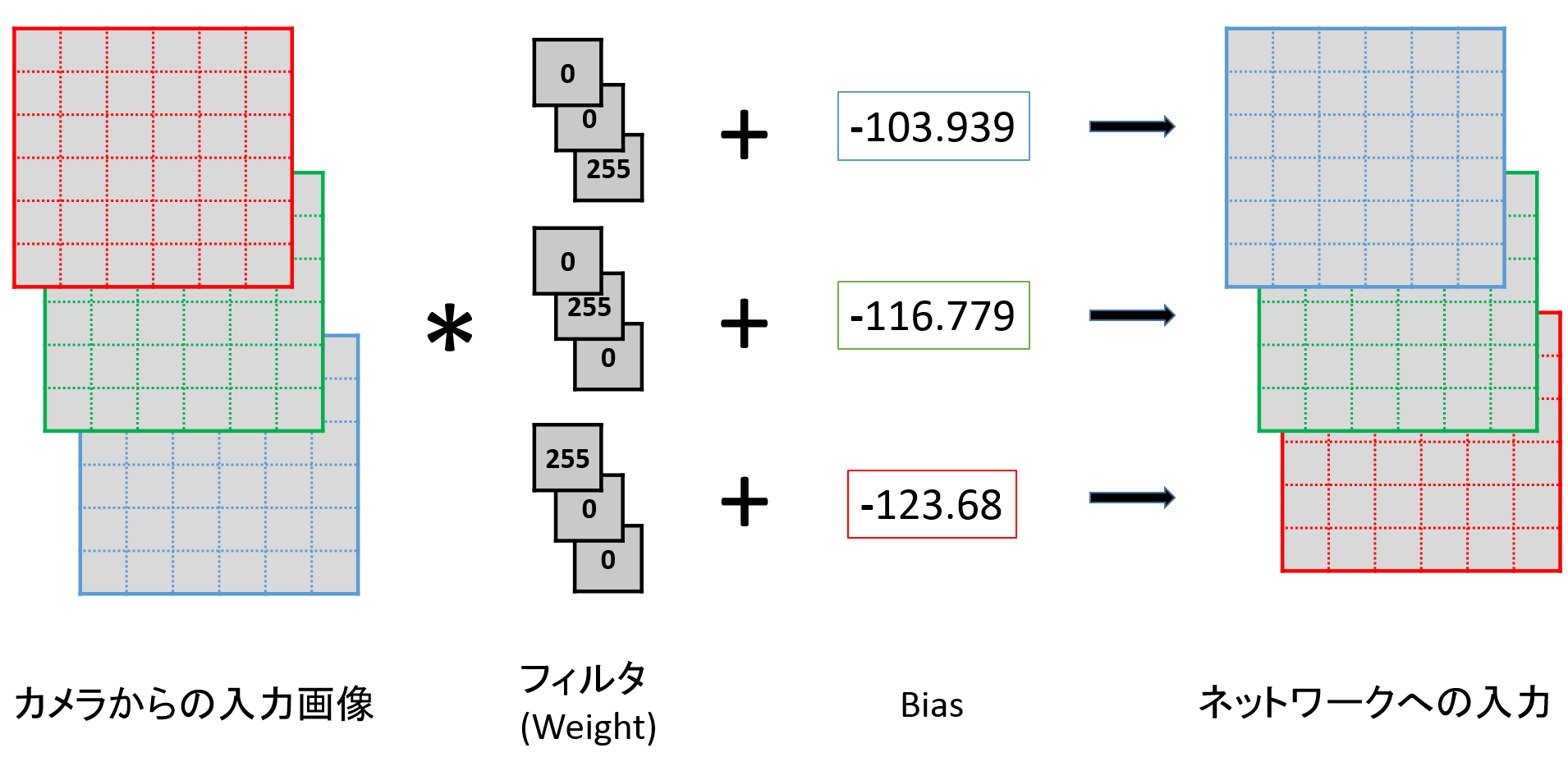
- カメラからの入力画像のチャネルはRGBで、学習済みモデルは入力画像のチャネルがBGRであるため、RGBからBGRに変換しなければならない。
- 学習済みモデルでは、入力画像から学習時のデータセットの平均値を引いた画像を入力としているため、カメラからの入力からも同様に平均値を引いた画像を入力としなければならない。
- MPSBilinearScaleNodeによって入力画像をリサイズした場合、入力画像の各ピクセル値が0から255ではなく0から1に正規化される。
これらの問題点を、VGG16の最初の畳み込み層であるconv1の前に畳み込み層conv0として実装することで、重みの演算部分で画像のチャネルをRGBからBGRに変更と各ピクセル値を0から255の範囲に戻し、バイアスの演算部分で学習時のデータセットの平均値を引くことにより解決している。conv0の概略図を図として以下に示す。
Figure:
MPSNNGraphを用いたVGG16の実装
 |
Figure:
conv0の概略図
 |
アプリケーションの実行時にViewControllerクラス内のviewDidLoad関数が呼び出され、この時にVGG16クラスを実行することで、図の部分が呼び出されてグラフが構築される。その後、カメラからの入力をMTLTextureとして受け取った時に、そのTextureをグラフのWithSourceImagesとして入力することによってグラフを実行し、結果を得ることができる。
本研究では、iOS上で画像認識システムを実装し、深層学習の演算処理にCPUのみを用いた実装とGPUのみを用いた実装の処理速度に関する比較実験と、深層学習の演算処理にGPUを用いる3種の実装方法の処理速度に関する比較実験の2つの実験を行った。ここではそれぞれの実験の設定と結果を示す。
それぞれの実験において、画像認識アプリケーションを実装し、認識に要した時間を求めることで比較を行った。認識時間は、計測を20回行いその平均時間とした。演算処理にGPUを用いた画像認識アプリケーションは、CoreMLとMPSとMPSライブラリの1つであるMPSNNGraphの3種についてそれぞれ実装した。ただし、MPSとMPSNNGraphは深層学習の演算処理を全てGPUのみで行うが、CoreMLは演算処理を隠蔽して行うため、処理の一部分をCPUで行っている可能性がある。演算処理にCPUのみを用いた実装とGPUのみを用いた実装の処理速度に関する比較実験では、評価用デバイスをiPad pro(9.7インチ A9X RAM2GB)、認識ネットワークをAlexNet[#!alexnet!#]とした。処理をGPUのみで行う画像認識アプリケーションはMPSNNGraphを用いて実装し、処理をCPUのみで行うChainer2Cを用いて実装した画像認識アプリケーションと比較した。演算処理にGPUを用いる3種の実装方法の比較実験においては、評価用デバイスをiPhone 8 Plus(A11 RAM3GB)、認識ネットワークをVGG16[#!vgg16!#]とした。
2つの実験の共通の設定と各実験固有の設定を以下にまとめる。
![\begin{itembox}[l]{2つの実験の共通設定}
・計測する時間は、認...
...�計測は20回行い、その平均を認識時間とした。\\
\end{itembox}](main-img1.png)
![\begin{itembox}[l]{CPUとGPUの違いによる処理速度の比較実験の設�...
...��プリケーションは、MPSNNGraphを用いて実装した。
\end{itembox}](main-img2.png)
![\begin{itembox}[l]{GPUを用いた実装方法の違いによる処理速度の�...
...�は、MPSNNGraph、MPS、CoreMLの3種類で実装を行った。
\end{itembox}](main-img3.png)
MPSNNGraphを用いてAlexNet[#!alexnet!#]ネットワークによる物体認識アプリケーションを作成し、計測を20回行って認識時間[msec]の平均を求めた結果を表として以下に示す。表より、深層学習の演算処理をCPUのみで行った場合に比べてGPUのみで行った場合の方が約3.7倍の速度で実行可能という結果が得られた。
Table:
AlexNetによる物体認識の認識時間 [msec]
| 実装方法 |
平均認識時間 |
|
|
| Chainer2C[#!c2calex!#] |
134.9 |
|
|
| MPSNNgraph |
36.4 |
|
|
MPSNNGraph、MPS、CoreMLを用いてそれぞれVGG16[#!vgg16!#]ネットワークによる物体認識アプリケーションを作成し、計測を20回行って認識時間[msec]の平均を求めた結果を表として以下に示す。表より、本研究のコンバータChainer2Sを利用して作成したMPSNNGraphを利用して実装した物体認識アプリケーションが最も速い108.99[msec]という結果となった。
Table:
VGG16による物体認識の認識時間 [msec]
| 実装方法 |
平均認識時間 |
最速認識時間 |
最遅認識時間 |
| CoreML |
144.87 |
134.47 |
151.00 |
| MPS |
155.21 |
146.72 |
170.00 |
| MPSNNGraph |
108.99 |
107.67 |
110.68 |
深層学習の演算処理をCPUのみで行った場合とGPUのみで行った場合とを比較した実験結果から、演算処理をCPUのみで行った場合に比べて演算処理をGPUのみで行った場合の方が約3.7倍高速であることが分かる。これはGPUがCPUよりもベクトル演算や並列処理に適しているからと考えられる。そのため、AlexNet[#!alexnet!#]で推論を一回行う時に必要な演算量が約11億回であり、それよりも一回の推論に必要な演算量が増えるネットワークにおいては実行速度の差が更に開くことが予想される。このことから、最新の深いネットワークをモバイル端末上に実装する場合には、深層学習の演算処理にGPUを用いた実装をする必要があると考えられる。
深層学習の演算処理にGPUを用いた実装方法の違いによる処理速度を比較した実験結果から、全て演算処理にGPUを用いているにも関わらずMPSNNGraphによる実装が取り分け速いことが分かる。CoreMLはネットワーク内部の処理をどのように行っているかが隠蔽されているため今回の結果となった明確な理由は分からない。しかし、MPSNNGraphとMPSとの差は、MPSNNGraphがグラフ構造を利用していることで、演算処理の最適化が行われいていることによるものだと予想できる。従って、16層からなるVGG16[#!vgg16!#]ネットワークよりも深いResNet50[#!resnet!#]などの最新のネットワークではグラフ構造を利用したことによる恩恵が大きくなると考えられる。
深層学習フレームワークのChainerを用いて計算機上で深層学習の学習を行い、生成されたモデルファイルからネットワーク部分のSwift言語のコードとパラメータを格納したバイナリファイルを生成するコンバータChainer2Sを作成した。これにより、iOS端末上で容易に深層学習の推論を行うことを可能にした。また、MPSNNGraphを用いて深層学習の演算処理を全てGPUで行うことで、VGG16ネットワーク[#!vgg16!#]で108.99[msec]という高速実行を可能にした。
本研究で行った深層学習の演算処理をCPUのみで行った場合とGPUのみで行った場合の処理速度の比較実験から、AlexNetネットワーク[#!alexnet!#]における推論時間がCPUのみの場合よりもGPUのみの場合の方が3.7倍高速であり、iOS上に深層学習アプリケーションを実装する際のGPU利用の必要性を示した。また、演算処理にGPUを用いる実装方法の違いによる処理速度の比較実験から、iOS上に深層学習アプリケーションを実装する時には、MPSNNGraphを用いる実装が最適な実装方法であることを明らかにした。
現在、本研究で作成したコンバータChainer2SはResNet[#!resnet!#]のような枝分かれのあるネットワークには対応していない。また、MPSNNGraph側で対応しているレイヤー種類の全てに対応しているわけではない。そのため、今後枝分かれのあるネットワークやより多くのレイヤーに対応することでより複雑で深いネットワークモデルを利用可能となり、物体認識の精度向上を図ることができるようになり、画像変換など様々なタスクの深層学習アプリケーションが開発可能となる。よって、コンバータの枝分かれのあるネットワークと多くのレイヤー種への対応が課題として考えられる。
更に、現在MPSNNGraphでは自ら新規にフィルターノードを作成することは不可能であり、全てのフィルターに関するノードが存在しているわけではない。そのため、現状ではあまり一般的でないレイヤーや新規に開発されたレイヤーはMPSNNGraphのアップデートで追加されるまで使用することはできない。これを解決するためには、加算及び乗算を行うノードや現在利用可能なフィルターノードなどを組み合わせて同義の演算を実装するという方法があるが、これを行うとコードが非常に難解になってしまう。これをコンバータ側で生成可能にすることで、どのようなネットワークモデルにも対応可能とすることも課題として考えられる。
No References!
- 畳み込み層のノード
- MPSCNNBinaryConvolutionNode
- MPSCNNConvolutionNode
- MPSCNNConvolutionTransposeNode
- プーリング層のノード
- MPSCNNPoolingAverageNode
- MPSCNNDilatedPoolingMaxNode
- MPSCNNPoolingL2NormNode
- MPSCNNPoolingMaxNode
- MPSCNNPoolingNode
- 全結合層のノード
- MPSCNNBinaryFullyConnectedNode
- MPSCNNFullyConnectedNode
- 活性化関数のノード
- MPSCNNNeuronAbsoluteNode
- MPSCNNNeuronELUNode
- MPSCNNNeuronHardSigmoidNode
- MPSCNNNeuronLinearNode
- MPSCNNNeuronPReLUNode
- MPSCNNNeuronReLUNNode
- MPSCNNNeuronReLUNode
- MPSCNNNeuronSigmoidNode
- MPSCNNNeuronSoftPlusNode
- MPSCNNNeuronSoftSignNode
- MPSCNNNeuronTanHNode
- MPSCNNNeuronNode
- ソフトマックス層のノード
- MPSCNNCrossChannelNormalizationNode
- MPSCNNLocalContrastNormalizationNode
- MPSCNNSpatialNormalizationNode
- MPSCNNNormalizationNode
- アップサンプリング層のノード
- MPSCNNUpsamplingBilinearNode
- MPSCNNUpsamplingNearestNode
- リサンプリングのノード
- MPSNNBilinearScaleNode
- MPSNNLanczosScaleNode
- MPSNNScaleNode
- MPSImageTransformProvider
- 結合関数のノード
- 算術ノード
- MPSNNAdditionNode
- MPSNNSubtractionNode
- MPSNNMultiplicationNode
- MPSNNDivisionNode
- MPSNNBinaryArithmeticNode
- ベースクラス
Table:
MPSNNGraphを用いた実装におけるAlexNetの認識時間 [msec]
| 実装方法 |
MPSNNGraph |
|
|
| 計測1回目 |
37.92 |
|
|
| 計測2回目 |
35.63 |
|
|
| 計測3回目 |
34.48 |
|
|
| 計測4回目 |
39.36 |
|
|
| 計測5回目 |
42.61 |
|
|
| 計測6回目 |
37.58 |
|
|
| 計測7回目 |
37.56 |
|
|
| 計測8回目 |
34.60 |
|
|
| 計測9回目 |
34.15 |
|
|
| 計測10回目 |
35.59 |
|
|
| 計測11回目 |
36.15 |
|
|
| 計測12回目 |
35.14 |
|
|
| 計測13回目 |
34.98 |
|
|
| 計測14回目 |
35.92 |
|
|
| 計測15回目 |
35.71 |
|
|
| 計測16回目 |
35.36 |
|
|
| 計測17回目 |
36.49 |
|
|
| 計測18回目 |
36.16 |
|
|
| 計測19回目 |
35.91 |
|
|
| 計測20回目 |
36.34 |
|
|
Table:
処理にGPUを用いた実装方法のVGG16の認識時間 [msec]
| 実装方法 |
MPSNNGraph |
MPS |
CoreML |
| 計測1回目 |
108.01 |
154.58 |
138.32 |
| 計測2回目 |
108.10 |
163.07 |
145.33 |
| 計測3回目 |
109.17 |
150.04 |
145.99 |
| 計測4回目 |
110.39 |
157.56 |
140.88 |
| 計測5回目 |
109.74 |
162.90 |
144.74 |
| 計測6回目 |
110.68 |
154.69 |
147.91 |
| 計測7回目 |
110.12 |
149.14 |
144.85 |
| 計測8回目 |
109.27 |
155.21 |
151.00 |
| 計測9回目 |
107.67 |
151.92 |
143.00 |
| 計測10回目 |
110.34 |
156.71 |
134.47 |
| 計測11回目 |
108.67 |
146.72 |
144.98 |
| 計測12回目 |
107.61 |
149.02 |
144.54 |
| 計測13回目 |
108.74 |
152.56 |
143.45 |
| 計測14回目 |
108.90 |
170.00 |
147.29 |
| 計測15回目 |
108.44 |
155.56 |
150.01 |
| 計測16回目 |
108.70 |
150.81 |
149.05 |
| 計測17回目 |
109.00 |
152.90 |
140.75 |
| 計測18回目 |
108.92 |
153.52 |
152.26 |
| 計測19回目 |
109.00 |
157.03 |
142.53 |
| 計測20回目 |
108.31 |
160.23 |
146.03 |
Footnotes
- ... iOS1
- https://github.com/aleph7/caffe
- ...、TensorFlow2
- https://www.tensorflow.org/mobile/
- ...、OpenCV3
- https://github.com/opencv/opencv/wiki/Deep-Learning-in-OpenCV
- ...などがある。また、既存のフレームワーク上に設計され、モバイルへの適用が考慮されたものとしてCaffe24
- https://github.com/caffe2/caffe2
- ...
CoreMLは、iOS11から新しく追加された機械学習API群である5
- https://developer.apple.com/documentation/coreml